Data Analysis Tool
There are two possibilities to run the Data Analysis Tool:
- locally:
- download the Data Analysis Tool from the GitHub repository: https://github.com/CAM-E-L/DataAnalysis (use
.gitor download it manually -> green button "<>Code" -> "Download ZIP") - if not already installed, download R and RStudio
- open the file
app.R, install packages if needed, click on "Run App"
- download the Data Analysis Tool from the GitHub repository: https://github.com/CAM-E-L/DataAnalysis (use
- online (! disadvantage: App is way slower):
- open the link: https://fennapps.shinyapps.io/DataAnalysis/
Within the CAM app you are guided and within every implemented module (see below) you have module specific information ("> Information" button in the sidebar panel). The single modules / functionalities are explained in more detail below with specific examples.
If you want to change or extend single functions, please check out the readme file of the folder "additional scripts" in the GitHub repository: https://github.com/CAM-E-L/DataAnalysis/tree/main/additional%20scripts
Data-structure of uploaded CAMs
After uploading your raw CAM data (see next section) you can click on the module specific option "> Descriptive" to get an overview over your uploaded data in the form of dynamic tables. Here you can see that a CAM data set consists of nodes (also called "concepts") and connectors data set (for details of the data structure within the Data Collection Tool see "Data-structure of CAMs" ):
Nodes data set contains all concepts drawn in the CAM and the following variables are considered in the Data Analysis Tool:
| Parameter | Meaning |
|---|---|
| CAM | Character string (ID) that is assigned by the Data Collection Tool to the CAM. |
| participantCAM | ID that is assigned by the researchers to the CAM (usually ID is generated in the previous study part). |
| dateCAMcreated | Date when CAM was created. |
| dateConceptCreated | Date when concept was created. |
| id | Random character string (ID) that is assigned by the Data Collection Tool to the single node. |
| text | Text written by the participant. |
| value | Valence given by the participant ranging from [-3,3]. |
| comment | Comment given by the participant. |
| date | Date of creation. |
| x_pos | x-coordinate of the drawn concept. |
| y_pos | y-coordinate of the drawn concept. |
| predefinedConcept | If any of the following 3 variables are TRUE, the concept is predefined by the researcher. |
| isDraggable | If concept is moveable (set by researcher). |
| isDeletable | If concept is deletable (set by researcher). |
| isTextChangeable | If text of concept is changeable (set by researcher). |
| isActive | TRUE if concept was not deleted by participant. |
Remark: By default all concepts deleted by the participants are removed from the nodes data set (isActive is a constant only containing TRUE).
Connectors data set contains all connectors drawn in the CAM and the following variables are considered in the Data Analysis Tool:
| Parameter | Meaning |
|---|---|
| CAM | Character string (ID) that is assigned by the Data Collection Tool to the CAM. |
| participantCAM | ID that is assigned by the researchers to the CAM (usually ID is generated in the previous study part). |
| dateCAMcreated | Date when CAM was created. |
| dateConnectorCreated | Date when connector was created. |
| id | Random character string (ID) that is assigned by the Data Collection Tool to the single connector. |
| date | Date of creation. |
| daughterID | ID of the concept to which the connection is pointing. |
| motherID | ID of the concept from which the connection originates. |
| intensity | Thickness of line. |
| agreement | TRUE if it a strengthening connection (solid line), FALSE if it is a inhibitory connection (dashed line). |
| isBidirectional | TRUE if connection is bidirectional. |
| isDeletable | If concept is deletable (set by researcher). |
| isActive | TRUE if connector was not deleted by the participant. |
Remark: By default all connectors deleted by the participants are removed from the connectors data set (isActive is a constant only containing TRUE).
Get duration over which a CAM was drawn
You could apply the following R Code to get the duration over which a CAM was drawn:
vec_duration <- c()
for(c in unique(CAMfiles[[1]]$CAM)){
print(c)
tmp_diffConcepts <- CAMfiles[[1]][CAMfiles[[1]]$CAM == c,"dateConceptCreated"] -
CAMfiles[[1]][CAMfiles[[1]]$CAM == c,"dateCAMcreated"]
tmp_diffConnectors <- CAMfiles[[2]][CAMfiles[[2]]$CAM == c,"dateConnectorCreated"] -
CAMfiles[[2]][CAMfiles[[2]]$CAM == c,"dateCAMcreated"]
print(max(c(tmp_diffConcepts, tmp_diffConnectors)))
vec_duration[[c]] <- max(c(tmp_diffConcepts, tmp_diffConnectors))
}
Remark: The variables "dateConceptCreated" and "dateConnectorCreated" could be used to check the drawing process of a CAM (e.g., if all concepts were drawn before connectors were added).
Suffix notation
Internally the Data Analysis Tool attaches a suffix to summarized words (see below), whereby a suffix is placed after the end of a word. For example after summarizing the word "Cost", which was drawn by multiple participants, some participants rated the word as negative, neutral, ambivalent or even positive and the word would be internally represented as follows:
Cost_negative
Cost_neutral
Cost_ambivalent
Cost_positive
It is a source of confusion, but it is of most importance to distinguish between the semantics and the valence of a word. It is highly probable that a participant who rated the drawn concept "Cost" positive has something different in mind than a participant who rated it negatively.
Implemented features overview
In our experience it is necessary to guide the researcher (or assistent) through the analysis process, because the analysis of CAM data is relatively difficult and the individual modules build on each other logically. The following figure visualizing all the implemented features separated for the (a) pre-processing and (b) analysis part (click on figure to enlarge it in new tab):
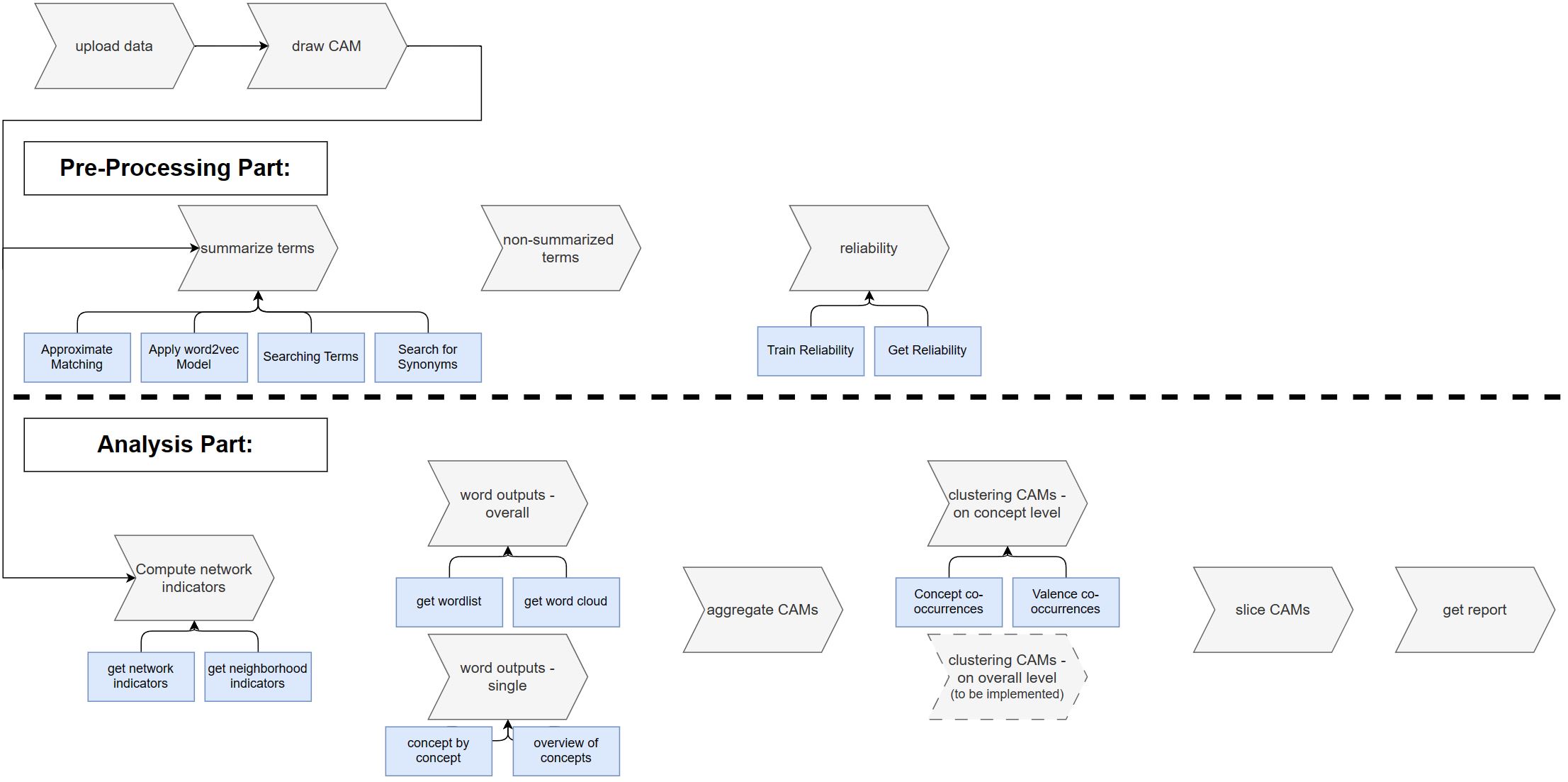
As visible in the picture the researcher needs always to upload the raw CAM data (and the protocol) and to draw all the CAMs. Note: for better visibility, the "descriptive functions" of the individual modules are not shown in the figure.
Import, draw CAMs part
When starting the Data Analysis Tool in the first module "upload data" the researcher can import the raw CAM data (and the protocol). After uploading the files the researcher can click on one of the following buttons:
- Preprocessing Part: using multiple modules it is possible to summarize the CAM data semi-automatically
- Analysis Part: the (summarized) data can be subsequently analyzed and visualized using multiple implemented functions
See for details the single sections.
Import CAM data
Core-functions module: After starting the Data Analysis Tool by clicking on "2) Upload a raw CAM data set" the researcher can upload a raw CAM data set. Internally the data set is checked multiple times if it is a valid CAM data set. If a protocol already exists it is mandatory to upload the protocol before uploading the raw CAM data.
Module options:
- "> Descriptive:" after a valid CAM dataset has been uploaded, several descriptive statistics can be looked at. Within the dynamic tables it is possible to sort the data according to single variables of search within the nodes and connectors data set.
- "> Protocol stats:" after a valid protocol has been uploaded, several statistics for the protocol can be looked at, e.g., how often certain summary functions had been used
- "> Clean Valence:" by clicking on the button "clean Valence data" the R function "fix_ValenceData()" tries to automatically remove known problems within data sets of the previous CAM software Valence. Only needed if you have uploaded Valence data
Internally the following R functions are applied:
create_CAMfiles(datCAM = raw_CAM, reDeleted = TRUE, verbose = FALSE)
create_ValenceFiles(datBlocks = blocks, datLinks = links)
fix_ValenceData(dat_nodes, dat_connectors, dat_merged, verbose = FALSE)
- create_CAMfiles(): takes raw CAM data from Data Collection Tool as input, removes all the deleted concepts / connectors (
reDeleted), not printing this process to the console (verbose) - create_ValenceFiles(): takes raw CAM data from Valence software as input; Valences files are separate
.csvfiles for blocks (concepts) and links (connectors) - fix_ValenceData(): takes raw CAM data from Valence software as input and tries to automatically remove known problems within data sets of the Valence software, for example in Valence it is technically possible to draw multiple connections between concepts
Import protocol: remarks
After starting the Data Analysis Tool by clicking on "1) Upload your protocol" the researcher can upload a protocol generated by the Data Analysis Tool. Each time a researcher engages with the Data Analysis Tool, an automatic protocol is generated in the background, documenting all data pre-processing and analysis steps. By uploading the protocol and then the raw CAM data, all previously performed summary steps are reiterated and a researcher could continue pre-processing the CAM data. The protocol makes the summary process of the CAM data fully transparent for other researchers.
Example of protocol: The protocol is an internally JavaScript Object Notation (JSON) file and in the example it could be seen that the data was collected using the Data Collection Tool, no CAMs had been deleted and only the summary function "Searching terms" (see below) has been used, whereby the researcher searched for the word "cost" and found three terms (see also Suffix notation).
{
"sessionID": [
"6634852443"
],
"software": [
{
"software": [
"CAMEL"
],
"time": [
"2023-07-22 11:58:16"
]
}
],
"cleanValence": [
false
],
"deletedCAMs": {},
"currentCAMs": [
"5d7ebf9e93902b0001965912",
"5f50e3d60305bb088998b766",
"5c17c149f596b100011ca8b8",
"61112576c81c42b0409bd52a",
"56b4b530b2de2a000632cc5f"
],
"approximateMatching": {},
"searchTerms": {},
"findSynonyms": [
{
"time": [
"2023-07-22 11:58:24"
],
"wordsFound": [
"Cost_positive",
"damage_negative",
"Cost_ambivalent"
],
"superordinateWord": [
"Cost"
],
"noneSearchArgumentSynonyms": [
"none"
]
}
],
"modelwordVec": {}
}
Internally the following R functions are applied:
overwriteTextNodes(protocolDat, nodesDat)
- overwriteTextNodes(): if any summarize terms module functions had been applied and a protocol and raw data is uploaded, the text of the drawn concepts is internally summarized, the function overwrites the texts of the drawn concepts to superordinate terms
Draw CAMs
Core-functions module: After a researcher clicks on the button "Preprocessing Part" or "Analysis Part", she / he is forwarded to the "draw CAM" module. Here the researcher can draw all CAMs to get an overview of their data.
Module options:
- "> Draw R:" using the igraph package the CAMs are visualized. It is possible to draw the concepts at the same positions as those of the participants ("Yes" that positions should be considered), else a so-called force-directed graph drawing algorithm is applied. Furthermore, aesthetics like the relative size of the concepts (vertices) and of the edges (connectors) can be adjusted.
- If the researcher wants to delete single CAMs this is possible by marking all the CAMs, which should be deleted, with the button "un/delete CAM". It is recommended to save these CAMs as PDFs to upload them for example on OSF for transparency.
- The drawn CAMs could be ordered according to the mean valence, number of concepts / connectors, density or assortativity (see Network Indicators). These statistics are shown next to the individual plotted CAM.
- "> Draw JS:" to be implemented
Internally the following R function is applied:
draw_CAM(dat_merged = CAMfiles[[3]],
dat_nodes = CAMfiles[[1]],
ids_CAMs = "all", plot_CAM = FALSE, useCoordinates = TRUE,
relvertexsize = 5,
reledgesize = 1)
- draw_CAM(): takes raw CAM data as input, and draws all or only specific CAMs (
ids_CAMs). If "useCoordinates" isTRUEthe concepts are drawn on the same positions as those of the participants. If the function is used within RStudio by setting "plot_CAM" toTRUEall the CAMs are plotted within the Plots window
Pre-processing part
Using multiple modules it is possible to summarize the CAM data semi-automatically. This step is necessary if you aim to summarize the overall belief system depicted in the single collected CAMs regarding a certain topic.
After drawing the CAMs if the researcher clicks on the button "Continue" (bottom left within "draw CAM" module), she / he is forwarded to the "Summarize term module" with the following "Module options" (sidebar panel on the left):
Technical remarks, could be skipped without the loss of information: internally the following 3 R functions are applied in all summarize terms functions:
getlabels_appMatch(typeLabels = "positive",
getInput = optimalMatchSim(),
counter = ST_rv$counter, skipCond = ST_rv$skip,
dataSummarized = globals$dataCAMsummarized)
getSuperordinateWord(label_superordinate = "supordinateWord_appMatch",
label_Pos = "matches_positive_appMatch",
label_Neg = "matches_negative_appMatch",
label_Neut = "matches_neutral_appMatch",
label_Ambi = "matches_ambivalent_appMatch")
overwriteData_getProtocols(protocolCounter = ST_rv$protocolCounter_appMatch,
protocolDetailedOut = globals$detailedProtocolAM,
list_usedWords = globals$usedWords,
dataSummarized = globals$dataCAMsummarized,
searchArgument = input$maxStringDis,
searchType = "approximate",
label_superordinate = "supordinateWord_appMatch",
label_Pos = "matches_positive_appMatch",
label_Neg = "matches_negative_appMatch",
label_Neut = "matches_neutral_appMatch",
label_Ambi = "matches_ambivalent_appMatch")
The best way (in my opinion) to summarize the terms of the drawn concepts is to create bucket lists for all the summarize functions: bucket lists (using the R package sortable) are lists, which can contain in itself multiple other lists and allows drag-and-drop of terms between the different lists. For every concept to summarize in one iteration of the functions, the concepts are splitted according to their valence and the researcher can choose to remove single concepts / terms by moving the terms to the leftmost list using drag-and-drop. To fill in the bucket lists, get automatically the superordinate term and write a protocol / overwrite the summarized concepts the following three functions have been programmed:
- getlabels_appMatch(): create labels for bucket lists; getlabels_Search() is the identical function adjusted for the "Searching Terms" submodule and getlabels_Synonyms() was adjusted for the "Search for Synonyms" and "Apply word2vec Model" submodule
- getSuperordinateWord(): updates superordinate word, which is suggested below the bucket lists
- overwriteData_getProtocols(): a) overwrite summarized words, b) updates JSON protocol, c) get a detailed protocol and d) updates list of used words (which are displayed in a dynamic table at the bottom of the submodules, see below)
Approximate Matching
Central aim: By using approximate string matching, string distances between all unique concepts in the dataset are computed (using optimal string alignment) to find words which have been written slightly differently. Internally the stringdist package applies the optimal string alignment distance to compute the distances between two strings. For example, using this method the distance between “dreams” and “dreasm” (spelling error) would be d = 1, because the adjacent character “s” would be transposed. Such a procedure can be used to correct for spelling errors and find words, which are written in singular / plural.
How to use it:
- Click on "> Approximate matching", choose your maximum string distance and click on "start approximate string matching"
- it is recommended to increase step by step the maximum string distance and use this functionality several times
Please note that below all summarize functions a dynamic table is displayed after you summarized your first word, depicting in the following format all words you have already summarized: "fear (fear // Fear)" -> you summarized the words "fear" and "Fear" to the superordinate word "fear". The search functionalities of the table if you are looking for a specific word.
Internally no additional specific R function is applied.
Searching Terms
Central aim: By using search terms you apply so called regular expressions, which is a concise language to describe patterns of text. Applying the stringr package, which is part of tidyverse, for example, using the expression “[[:digit:]]”, all drawn concepts including any digits can be identified. For possible regular expressions to use, please read the "cheatsheet" of the stringr package and you can test combinations of regular expressions on the following webpage: https://regex101.com/.
How to use it:
- Click on "> Searching terms", enter your regular expression and click on "search"
- it is recommended to gradually increase the level of abstraction (progressively combine subcategories into thematic categories or superordinate categories)
Internally no additional specific R function is applied; however:
- by using the tryCatch() function it is checked if the provided regular expression is valid and if not a pop-up is shown, which requests the researcher to check the syntax
Search for Synonyms
Central aim: By using search for synonyms all synonyms for single-worded concepts are automatically searched and internally the English synonym dictionary included in the qdap R package is applied. For example, the concepts “war” and “conflict” would be identified as synonyms.
How to use it:
- Click on "> Search for synonyms", choose your language and click on "search for synonyms"
Internally the following R functions are applied:
SynonymList(vectorWords = tmp_text,
syn_dat = globals$dat_synonym$syn_English)
SummarizedSynonymList(listSynonyms = raw_SynonymList[[1]])
- SynonymList(): checks if single words are in the chosen dictionary, create a list of all synonyms
- SummarizedSynonymList(): removes overlapping words (duplicates)
Apply word2vec Model
Central aim: By applying a word2vec Model it is possible to compute the cosine similarity between drawn concepts pairwise to identify groups of drawn concepts with similar meaning. For example, cosine similarity between the words “responsibility” and “accountability” would be .70, whereby cosine similarity is ranging from -1 (opposite vectors) to 1 (proportional vectors). The word vectors are "included" in a pre-trained language model from the Python library spaCy and there are currently language models for 25 languages, see: https://spacy.io/models
How to use it:
- Click on "> Apply word2vec model", and follow the three steps (1) download summarized words, (2) download and run Python script and (3) upload the computed pairwise similarities. A more detailed explanation how to apply the function can be found on our GitHub page: https://github.com/CAM-E-L/DataAnalysis/tree/main/Python_word2vec
Internally no additional specific R function is applied; however:
- After uploading the computed pairwise similarities (step 3), a distance matrix is computed (euclidean) and a hierarchical cluster analysis (Ward's method) is applied to detect groups of similar words.
- Researchers are free to decide which amount of similarity is sufficient to indicate that it would be reasonable to summarize group / pair of words by specifying the cutting height of the dendrogram
5-step procedure to summarize CAM data
- Theoretically driven, possibly relevant super- and subordinate categories are identified on the basis of existing literature. Importantly, identical terms can thereby exhibit positive or negative valence depending on the structure of the argument, e.g. people appreciate or devalue “more free time” during Covid-19.
- Subsequently, all CAMs are drawn and individually examined. Possible additional superordinate and subordinate word categories are documented in the form of memos, which are recorded thoughts, ideas and hypotheses during the observation process. Additionally, by visual inspection of the CAMs with the lowest and highest mean valence it can be checked if people with strong attitudes use different lines of arguments.
- Data Analysis Tool modules: use Draw CAMs module
- Subcategories are formed iteratively, considering existing theories. In the initial coding step (3a), first categories are generated and their respective frequencies are documented. In the subsequent coding step (3b), related subcategories within the existing category system are combined, which cover similar thematic subjects. This process (3a, 3b) is repeated until all terms in the CAMs have been coded.
- Data Analysis Tool modules, we recommend to apply the modules in the following sequence: to correct for spelling errors / inconsistencies apply Approximate Matching; to automatically summarize your list of remaining unique concepts to superordinate words apply Search for Synonyms (using synonym dictionary) or Apply word2vec Model (using pre-trained language models); and finally to summarize related subcategories apply the Searching Terms module
- All subcategories that have been formed are combined to form topics at a higher level of abstraction
- Data Analysis Tool modules: apply the Searching Terms module; check finally for "non-summarized" terms using the Data Analysis Tool
- The results are presented in the form of tables and graphics.
We recommend to consider the following when summarizing concepts: to consider concepts’ valences and comments on the drawn concepts, it should be made explicit how negotiations and questions were handled (for example, whether "promotes the economy," "detrimental to the economy", and "economic consequences?" should belong to the same category "economy") and finally for a finer categorization, it should be made explicit whether concepts were categorized multiple times. The finer the categorization, the more the subjectivity of the researchers could influence the final categorization. To increase the reliability of categorization of multiple raters, an inter-rater agreement procedure is recommended. If needed, a categorization guideline should be created in advance.
Reliability module
To increase objectivity and due to time constraints, CAM data might be summarized by several independent raters. For such a case, we implemented a reliability module:
Train raters for summarizing of concepts
Central aim: A random sub-word list (e.g. 10% of all unique drawn concepts) can be generated. This Excel file can be downloaded and sent to the raters together with the proposed instructions (see within Data Analysis Tool).
How to use it:
- Click on top "reliability" -> "> Train Reliability", choose your settings to create the sub-word list and click on the "Download data" button top right.
- the following settings can be considered: select the ordering of the word list, if words should be split by given valence and if comments should be visible for your raters
Internally the following R function is applied:
create_wordlist(dat_nodes = globals$dataCAMsummarized[[1]],
dat_merged = globals$dataCAMsummarized[[3]],
order = input$a_Wordlist_Order,
splitByValence = tmp_splitByValence,
comments = tmp_includeComments,
raterSubsetWords = wordsOut,
rater = TRUE)
- create_wordlist(): creates (and returns) a word list separated by all unique words’ information regarding their mean valence and degree (plus the respective standard deviations). The following settings are considered:
order(alphabetic or frequency),splitByValence(split summarized words by the valence) andcomments(include comments). The rater arguments create only a subset of the total word list and add additional variables for the raters.
Compute inter-rater reliability
Central aim: After the raters summarized all concepts to superordinate words, reliability coefficients can be computed in this reliability submodule. Please note that the reliability coefficients only depend on the assumption that the same groups of words are summarized under one term each by different raters, but not that identical terms are used as superordinate categories by the raters. Three possible reliability coefficients can be computed: (a) Cohen's Kappa is pairwise computed between all raters by assuming a perfect match of overlapping groups of words or (b) Cohen's Kappa is pairwise computed by maximizing overlapping words, which have been summarized and finally (c) Fleiss’ Kappa and category-wise Kappa for different groups of overlapping words is computed. Additionally to these reliability statistics, summary statistics of the group of summarized words are given.
This information can be used to train raters, which could subsequently summarize the complete CAM dataset.
How to use it:
- Click on top "reliability" -> "> Get Reliability", and upload all your wordlists you have received by your raters (at least 2)
Internally the following R function are applied:
computeCohensKappa(files = data(),
numberRaters = length(data()))
computeCohensKappaMaximized(files = data(),
numberRaters = length(data()))
- computeCohensKappa(): Cohen's Kappa is pairwise computed between all raters by assuming a perfect match of overlapping groups of words
- Remark: when uploading rated wordlists at the bottom of the module you will see "Rating" variables containing, for example, "r0001r0002", which you mean that a rater has summarized the first and second concept under one superordinate term
- computeCohensKappaMaximized(): Cohen's Kappa is pairwise computed by maximizing overlapping words, which have been summarized and finally
Analysis part
The summarized data can be subsequently analyzed and visualized using multiple implemented modules. All the generated graphics / networks and even a report in APA7 format (see below) could be used for articles or reports:
Network Indicators
The level of the network indicators is indicated by the respective suffix:
- "X_micro:" network indicator extracts features at the individual node and edge level
- "X_mezzo:" extracts features from communities (meaningful subnetworks)
- "X_macro:" extracts features from the global network level
Two types of network indicators with their respective descriptive statistics can be computed:
Compute network indicators
Central aim: Compute 33 different network indicators (e.g., mean valence, density etc.) on an overall CAM level (macro). Additionally, select one or several concepts and calculate network indicators on an individual concept level (micro):
| Network Indicator | Meaning |
|---|---|
| CAM_ID | Character string (ID) that is assigned once by the Data Collection Tool to each CAM. |
| participantCAM | Character string that is either created by the Data Collection Tool or transferred from another software (e.g., from questionnaire applications). Therefore, this column is anonymized for publications (e.g. replaced by a sequence number). |
| mean_valence_macro | The mean valence of all concepts. |
| mean_valence_normed_macro | The normed mean valence of all concepts, whereby all concepts with positive valences get +1, and all concepts with negative valence -1. |
| density_macro | The density of a CAM refers to the ratio between the actual number of edges and the maximum possible number of edges in the CAM. |
| transitivity_macro | Transitivity measures the likelihood that the neighboring vertices of a vertex are connected. This is also known as the clustering coefficient. |
| centr_degree_macro1 | Centralization measure according to the degrees of the vertices, whereby degree is defined as the number of connectors incident upon drawn concept. |
| centr_clo_macro1 | Centralization measure according to the closeness of the vertices, whereby closeness is defined as the shortest path between the concept and all other concepts in the CAM. |
| centr_betw_macro1 | Centralization measure according to the betweenness of the vertices, whereby betweenness quantifies the number of times a concept acts as a bridge along the shortest path between two other concepts. |
| centr_eigen_macro1 | Centralization measure according to the eigenvector centrality of the vertices, whereby eigenvector centrality puts more weights on concepts if these are already connected to more central concepts (higher degree). |
| meanDistance_directed_macro | Computes the average path length in a CAM by finding the shortest paths between all pairs of concepts, whereby directed paths in a directed CAM (contains an arrow) are considered. |
| meanDistance_undirected_macro | Computes the average path length in a CAM by finding the shortest paths between all pairs of concepts, whereby directed paths are not considered. |
| diameter_weighted_undirected_macro | The diameter of a CAM represents the length of the longest path, whereby the given weights to the connectors by the participants are considered and not the direction. |
| diameter_unweighted_undirected_macro | The diameter of a CAM represents the length of the longest path, whereby the given weights to the connectors by the participants are not considered and not the direction. |
| diameter_unweighted_directed_macro | The diameter of a CAM represents the length of the longest path, whereby the given weights to the connectors by the participants are not considered and the direction. |
| num_nodes_macro | Number of concepts. |
| num_nodes_pos_macro | Number of concepts with positive valence. |
| num_nodes_neg_macro | Number of concepts with negative valence. |
| num_nodes_neut_macro | Number of concepts with neutral valence. |
| num_nodes_ambi_macro | Number of concepts with ambivalent valence. |
| num_edges_macro | Number of connectors. |
| num_edges_solid_macro | Number of connectors with strengthening connections (solid lines). |
| num_edges_dashed_macro | Number of connectors with inhibitory connections (dashed lines). |
| num_edges_invaliddashed_macro | Number of connectors drawn violating the classical conceptualization of Thagard2. |
| meanWeightEdges_macro | The average weight of the connectors in a CAM is computed. |
| reciprocity_macro | Determines the likelihood of concepts in a directed CAM (arrows) to be mutually (reciprocal) linked. |
| assortativity_valence_macro | The coefficient ranges from [-1, 1], whereby positive values indicates that concepts with the same valence a tendency to connect with each other (level of homophily). The value -1 indicates a completely disassortative CAM. |
| assortativityDegree_macro | The coefficient ranges from [-1, 1], whereby positive values indicates that concepts with the same degree exhibit a tendency to connect with each other (level of homophily). The value -1 indicates a completely disassortative CAM. |
| largest_clique_length_mezzo3 | Length of the (all) the maximal cliques not considering arrows, whereby a clique is a subgraph that is complete (all concepts are connected to one another). |
| largest_clique_nums_mezzo3 | Number of all the maximal cliques, which have been drawn in the CAM. |
| largest_clique_names_mezzo3 | Name(s) of the concepts of (all) the maximal cliques, which have been drawn in the CAM. |
| degreetot_micro_X4 | The total degree of the chosen concept is determined. |
| valence_micro_X4 | The valence of the chosen concept is returned. |
| centr_clo_micro_X4 | The centralization value of the chosen concept is computed (see "centr_clo_macro" above). |
| transitivity_micro_X4 | The local clustering coefficient of the chosen concept is determined (see "transitivity_macro" above). |
1Centralization is a technique used to create a centralization measure for a CAM normally at the concept level based on the centrality scores of the concepts. However, in this case ("_macro") these measures are extended to the whole CAM (graph centralization).
2According to Thagard it makes no sense to (a) connect two concepts, one with positive, the other with negative valence by a strengthening connection (solid line), and (b) to connect concepts of the same valence (positive or negative) by a inhibitory connection (dashed line).
3Mezzo indicators (features from communities) are only computed if you define "largestClique=TRUE" in the "compute_indicatorsCAM()" function (see below).
4The suffix "X" is replaced by the chosen concept for which you want to get micro indicators (see within Data Analysis Tool).
How to use it:
- Click on top "network indicators" -> "> get network indicators", indicate for which concepts do you want to get micro indicators and click on "Compute network indicators"
- after computing network indicators you can click on "> get network descriptives", you will get an APA table with multiple summary statistics, a correlation plot and you can search for significant correlations
Internally the following R function is applied:
compute_indicatorsCAM(drawn_CAM = NULL,
micro_degree = NULL,
micro_valence = NULL,
micro_centr_clo = NULL,
largestClique = FALSE)
- compute_indicatorsCAM(): network indicators are computed, by specifying
micro_degree,micro_valenceormicro_centr_cloyou will get the respective micro statistics for the chosen concepts; settinglargestCliqueto TRUE you will get a mezzo indicator containing all the names of the largest clique (where all concepts are connected with each other)
Compute neighborhood network indicators
Central aim: Compute several variants (in total 6 variants) of average valences over group of concepts, whereby "X" is a placeholder for your chosen concept:
- mean_1_X, mean_2_X: compute the mean valence over the neighborhood of order 1 / 2 with no adjustments
- mean_1_dashed_X, mean_2_dashed_X: compute the mean valence over the neighborhood of order 1 / 2 with adjustment for dashed lines if connected to positive concepts (see picture, explanation below)
- mean_2_weighted_X: compute the mean valence over the neighborhood of order 2 with weighting of neighborhood of second order (default .5), because we assume that's concepts further away have less relevance for the concept under consideration
- mean_2_weighted_dashed_X: compute the mean valence over the neighborhood of order 2 with weighting of neighborhood of second order (default .5) while adjusting for dashed lines (see picture, explanation below), because we assume that's concepts further away have less relevance for the concept under consideration
Example: This is helpful if you have specified two contradictory concepts in a study. In the example CAM below participants were surveyed regarding their motivation to use their “own car” or “public transport”. This is an interesting study design to analyze the perception of opposing poles or concepts. In such a case, it would not be meaningful to compute the overall mean valence. Instead, the mean valence over the neighborhood of the respective concept of the first or second order (one or two steps away, i.e., concepts that are directly connected to the respective concept are one step away) indicates the negative assessment of “public transport” and the mixed assessment of “own car” in this CAM. It is also possible to temporarily remove connections (and / or concepts) in order to not distort the neighborhood statistics (e.g., mean valence two steps away from the concept “own car”). Click on the example CAM to enlarge it in new tab - could take few seconds:
How to use it:
- Click on top "network indicators" -> "> get neighborhood indicators", indicate for which concepts do you want to get neighborhood indicators and click on "Compute neighborhood indicators"
- you can temporarily remove (a) connections (specify only 2 concepts between which you want to remove the connection) or (b) concepts (specify only 1 concept which you want to delete)
- after computing network indicators you can click on "> get network descriptives", you will get an APA table with multiple summary statistics and a correlation plot
Internally the following R function is applied:
compute_neighborhoodIndicatorsCAM(drawn_CAM = NULL,
weightSecondOrder = .5,
consideredConcepts = NULL,
sliceCAMbool = FALSE,
removeConnectionCAM = NULL,
removeNodeCAM = NULL)
- compute_neighborhoodIndicatorsCAM(): network neighborhood indicators are computed, by specifying
removeConnectionCAMor / andremoveNodeCAMa connection respective a concept is temporarily removed (sliceCAMboolis set to TRUE if any elements are removed); changing the value ofweightSecondOrderde/increases the weighting of the second order concepts;consideredConceptsis a vector containing all the concepts for which do you want to get neighborhood indicators
Adjusting for dashed lines:
In specific designs, participants associate a positive concept with predefined concepts, highlighted in blue within the image, using solid and dashed lines. Here, a participant linked "flexibility" (German: Flexibilität) with "certain timetable" (German: bestimmter Fahrplan) using a dashed line, implying a negative evaluation within this particular context. To address this, the valence of the concept is temporarily inverted (multiplied by -1).
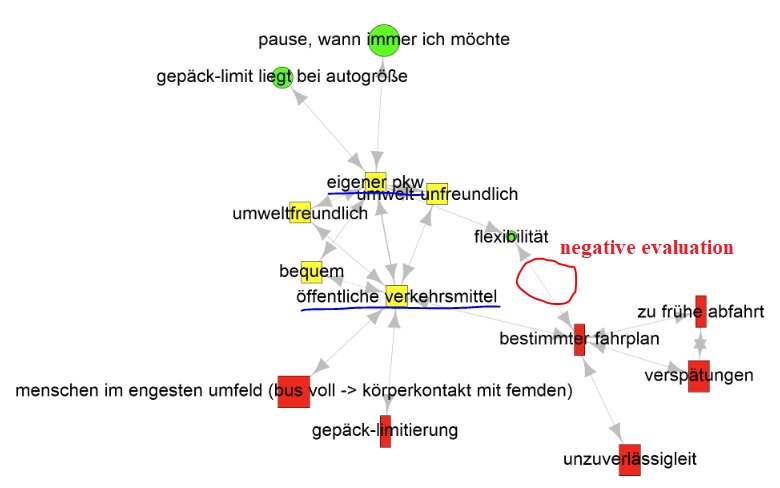
Word outputs overall
The two following functions summarize concepts on an overall semantic level:
Create wordlist
Central aim: Create a wordlist with summary statistics for each concept (mean / SD valence, mean / SD degree).
How to use it:
- Click on top "word outputs" -> "by words overall" -> "> get wordlist", choose your settings and click on "create wordlist"
- the following settings can be considered: select the ordering of the word list, if words should be split by given valence and if comments should be visible
Internally the following R function is applied:
create_wordlist(dat_nodes = CAMfiles[[1]],
dat_merged = CAMfiles[[3]],
useSummarized = TRUE,
order = NULL,
splitByValence = TRUE,
comments = TRUE,
raterSubsetWords = NULL,
rater=FALSE)
- create_wordlist(): creates (and return) a word list containing separated by all unique words information regarding their mean valence and degree (plus the respective standard deviations). The following settings are considered:
order(alphabetic or frequency),splitByValence(split summarized words by the valence) andcomments(include comments).
Create word cloud
Central aim: Create a word cloud of all your concepts in the dataset, whereby the colors indicate the concept’s mean valence.
How to use it:
- Click on top "word outputs" -> "by words overall" -> "> get word cloud", choose your settings and click on "create word cloud"
- the following settings can be considered: select the minimum frequency concepts have been drawn to be plotted, the maximum number of words to be plotted and define if the summarized or non-summarized words should be plotted
Internally no additional specific R function is applied.
Word outputs single words
The two following functions summarize single concepts on a semantic level:
Get graphics and summary statistics for concept by concept
Central aim: On a single concept level, a pie chart, bar plot and table for every summarized superordinate concept can be created to reflect and discuss the summary process of the CAM data.
How to use it:
- Click on top "word outputs" -> "by single words" -> "> concept by concept", choose for which summarized concept do you want to get an overview, define your settings and click on "get overview"
- the following settings can be considered: select the minimum frequency a single concept has been drawn in the CAMs to be plotted in the pie chart and bar plot / table (at least for the pie chart it is recommended not to show too many different concepts)
Internally no additional specific R function is applied.
Get summary statistics for all concepts
Central aim: For all single unique summarized concepts it is possible to create an table containing the respective frequencies of the drawn concepts separately for each CAM to easily recompute, for example, how often a certain concept with a specific valence (separated by N=total, Npositive=positive, and so on) was drawn within a CAM data set.
How to use it:
- Click on top "word outputs" -> "by single words" -> "> overview of concepts", click on "get complete overview"
Internally no additional specific R function is applied.
Aggregate CAMs
Central aim: By creating a so called “canonical adjacency matrix” CAMs according to different criteria (random CAMs, most positive / negative CAMs, CAMs with specific IDs) are aggregated, whereby the size of the concepts and the thickness of the connections is proportional to the frequency of the drawn concepts and the drawn pairwise connections respectively.
How to use it:
- Click on top "aggregate CAMs" -> "> aggregate CAMs", choose your settings and click on "aggregate CAMs"
- the following settings can be considered: select if you want to split your summarized concepts by the valence and if you want to (a) aggregate random CAMs, (b) aggregate the most positive or negative CAMs or (c) choose specific CAMs you want to aggregate
Internally the following R functions are applied:
aggregate_CAMs(dat_merged = CAMfiles[[3]],
dat_nodes = CAMfiles[[1]],
ids_CAMs = selectedIDs)
rename_identicalTerms(dat_nodes = CAMfiles[[1]],
drawn_CAM = CAMdrawn)
- aggregate_CAMs(): aggregate the CAMs with IDs provided by
ids_CAMs - rename_identicalTerms(): function renames identical terms within individual CAMs; for example, in a single CAM the concept “cost” is written twice, these two concepts would be renamed to “cost_1”, “cost_2”, whereby the concepts are named in descending order of their degree.
Clustering CAMs on concept level
CAMs can be clustered on concept level (terms written by participants):
Concept co-occurrences
Central aim: The co-occurrences of concepts within individual CAMs is computed by setting up multiple contingency tables between single pairs of summarized concepts.
Example: Imagine a CAM dataset in which multiple concepts were summarized to the superordinate concepts “do something” and “accountability”. In total, the concept “do something” was drawn 18 times (after summarizing) and the concept “accountability” 13 times. Seven participants drew both concepts together in their respective CAMs. This results in a 2x2 table depicted in the table below. A significant phi coefficient ( = .27, p <. 05) indicates that both concepts were drawn together disproportionately often. This computation is repeated for all concepts pairwise and the pairwise phi coefficients are visualized within a heatmap.
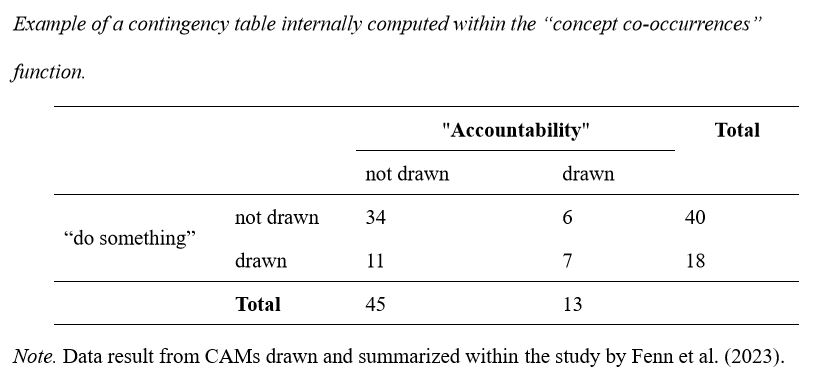
The table is extended if also the valence of the concepts is considered (no 2x2 table, but 2*d x 2*d, whereby d are the different valences of the respective concepts). If valences are considered Cohen's Kappa is computed, if not then the Phi coefficient is computed.
How to use it:
- Click on top "clustering CAMs" -> "on concept level" -> "> Concept co-occurrences", choose your settings and click on "draw Heatmap"
Internally the following R functions are applied:
listConcepts(datCAM = CAMfiles[[1]],
useSummarized = TRUE,
removeSuffix = TRUE)
countDuplicates(concepts = conceptsDF,
orderFrequency = FALSE)
binaryEncoding(conDF = conceptsDF,
duplDF = duplicateDF)
metricEncoding(conDF = conceptsDF,
duplDF = duplicateDF)
phiCoefficient(var1,
var2)
pearsonCoefficient(var1,
var2)
cohensKappa(var1,
var2)
correlationTable(conList = duplicateDF,
inputTable = binaryDf,
CorrFUNC,
considerValence = TRUE,
datNodes = NULL)
- listConcepts(): creates (and return) data frame of concepts per CAM (column) from CAM-data
- countDuplicates(): returns a data frame with all concepts mentioned in more than one CAM (columns "concept") and the number of CAMS where it occurs (column "numCAMoccurences")
- binaryEncoding(): creates a Table with binary encoding for duplicate concepts. e.g., each concept mentioned more than once is a column, each CAM is a row; if the concept is mentioned in the respective CAM, cell is 1, if not cell is 0
- metricEncoding(): creates a Table with metric encoding for duplicate concepts. e.g., each concept mentioned more than once is a column, each CAM is a row; if the concept is mentioned in the respective CAM, cell is X, whereby X is the number of occurrence of concepts in the respective CAM if not cell is 0
- phiCoefficient(): calculates Phi coefficient and p-value (chi-square) and returns both in a vector
- pearsonCoefficient(): calculates pearson coefficient and p-value and returns both in a vector
- cohensKappa(): calculates Cohen's Kappa
- correlationTable(): builds a list that contains two dataframes: one that contains the correlation coefficients for the pairwise co-occurence of all concepts and one the respective p-values
Valence co-occurrences
Central aim: The mean valence over all summarized concepts is computed. These mean variables are z-transformed and a hierarchical cluster analysis (euclidean distance + Ward's method) for all summarized concepts which were drawn at least two times is applied. The resulting cluster solution can be interpreted by the average mean differences on the mean variables of the summarized concepts. Such analysis could help to indicate if identical named / summarized concepts of certain supporters / opponents (e.g., on belief in climate change) have different mean valence.
How to use it:
- Click on top "clustering CAMs" -> "on concept level" -> "> Valence co-occurrences", click on "get valence co-occurrences"
Internally no additional specific R function is applied; however:
- Researchers are free to decide how many clusters would be reasonable to differentiate between the average valences of the single concepts by specifying the cutting height of the dendrogram
Slice CAMs
Central aim: If you have a CAM structure, which can be separated (e.g. pre-defined opposing concepts), like in the example CAM in the "Compute neighborhood network indicators" section, the module could be applied. CAMs are automatically separated according to two possible criteria: (a) delete a connection between two concepts, and / or (b) delete a concept. The example CAM could be separated by deleting the connection between the two opposing concepts “own car” and “public transport”. The so generated datasets could be uploaded again to the Data Analysis Tool if the resulting sub-CAMs (e.g. to investigate reasons to use the “own car”) should be summarized separately.
How to use it:
- Click on top "slice CAMs" -> "> slice CAMs", choose your settings and click on "Slice CAMs"
- the following settings can be considered: (a) delete a connection between two concepts (maximum one connection), and / or (b) delete a concept (maximum one concept)
Internally the following R functions are applied:
sliceCAM(singleCAM = drawnCAMs[[i]],
singleCAMid = names(drawnCAMs)[i],
removeConnection = connectionToRemove,
removeNode = nodeToRemove,
plot = FALSE,
verbose = FALSE)
sliceAllCAMs_combined(CAMfilesList = globals$dataCAMsummarized,
drawnCAMs = drawnCAM(),
connectionToRemove = tmp_RemoveConnection_SC,
nodeToRemove = tmp_RemoveConcept_SC,
centralConceptsSubgraphs = input$CentralWords_SC,
plot = FALSE)
sliceAllCAMs_seperated(slicedCAMs = slicedCAMs_combined,
centralConceptsSubgraphs = input$CentralWords_SC,
plot = FALSE)
- sliceCAM(): function slices single CAMs according to arguments in
removeConnection(remove single connection) and / orremoveNode(remove single concept). - sliceAllCAMs_combined(): function applies internally sliceCAM() to slice CAMs and checks if two network components (groups of concepts) and if every component includes one of the expected central concepts (defined in
centralConceptsSubgraphs) - sliceAllCAMs_seperated(): takes the output of the sliceAllCAMs_combined() function and returns a list containing the merged datasets for the expected central concepts
Remark: sliceAllCAMs_combined() and sliceAllCAMs_seperated() only returns the data for CAMs where the slicing process was successful
Get Report
Central aim: Applying the module a report in APA 7 format is created containing a description of the CAM dataset, statistics of the summary process (preprocessing part of the Data Analysis Tool) and (if desired) statistics of individual concepts. This report could be copied to a scientific publication or sent to interested collaborators.
How to use it:
- Click on top "get Report" -> "> Get Report", choose your settings and click on "get Report"
- the following setting can be considered: select the concepts for which you want to receive additional statistics (alphabetically sorted)
- you should provide the module the number of predefined concepts in your study, as such that the statistics of how many of the pre-defined concepts had been removed is correct
Internally no additional specific R function is applied; however:
- internally the compute_indicatorsCAM() function is applied
Future features
The next step for the Data Analysis Tool is the implementation of network similarity algorithms, which would make it possible, for example, to identify subgroups of people within the CAM data, who believe / disbelieve in climate change, which is a highly polarized issue. Such analysis could help to understand the respective mental models of polarized groups and to combat climate change disinformation.
If you are missing a specific feature for your study and do not know how to implement it, we are happy to hear from you: cam.contact@drawyourminds.de